Diferenciando json.loads de json.load e uma pitada de BigQuery
Se você nunca entendeu a diferença entre json.loads() e json.load() chegou a hora de entender! Na colinha de hoje vamos aprender a diferenciar esse métodos deliciosos.
JSON
Se você chegou até aqui, provavelmente já sabe o que é o JSON. Mas caso não saiba, bora recapitular: O JSON (JavaScript Object Notation ou Notação de Objetos JavaScript) é um formato leve de troca de dados. É fácil de ler e escrever, o que ajuda a ser usado por humanos além de também ser fácil de ser criado e interpretado por máquinas.
Se você já usou APIs provavelmente trocou dados com elas usando este formato. A maioria das linguagens de programação moderna oferece suporte de alguma forma a JSON. No caso do Python, existe uma estrutura que é quase a mesma coisa que um objeto JSON: o dicionário.
Módulo JSON no Python
Além de uma estrutura de dados, Python também traz de fábrica um módulo para manipulação de JSONs. Para utilizar esse módulo basta fazer o seguinte:
import json
Dentre os vários métodos, existem dois que são o foco dessa colinha de hoje .loads() e .load() que apesar de muito semelhantes em resultado, são diferentes em modo de funcionamento.
Dados
Mas antes de começar, vamos pegar alguns dados. Esses dias eu tava dando uma olhada no BigQuery, que entre muitas coisas legais que a ferramenta permite fazer, também da acesso a uma enormidade de dados públicos. Dentre eles dados do GitHub. Muitos desses dados estão disponíveis via API do próprio GitHub, mas se quiser aprender a mexer no BigQuery, eles já disponibilizam os dados lá dentro pra gente:
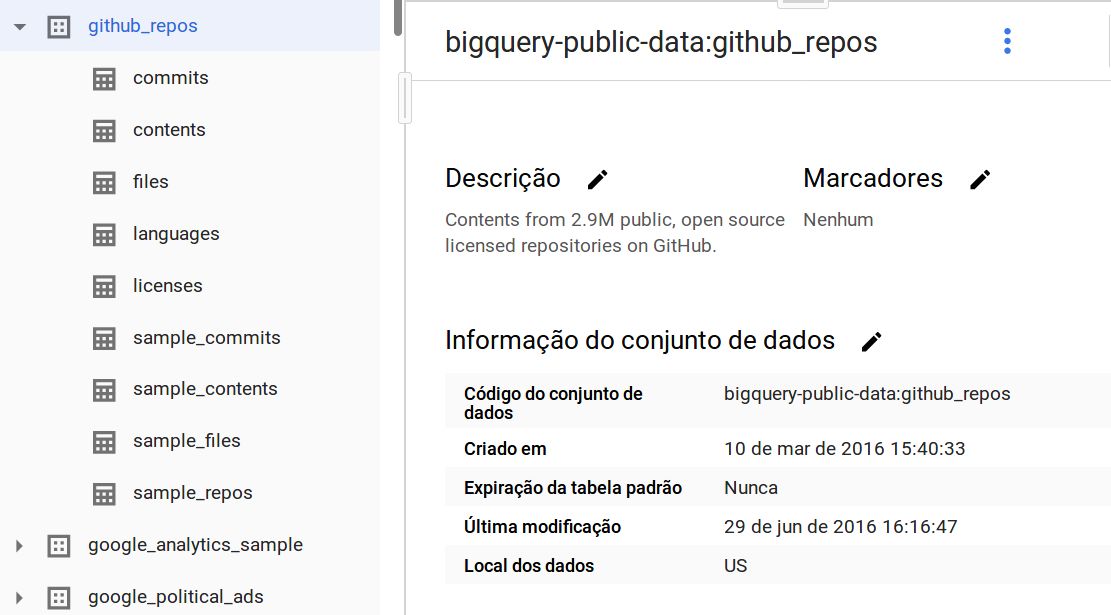
Muito fofo né? Dá pra ver pela imagem acima que o conjunto de dados github_repos contém 9 tabelas. Dentre elas uma tabela chamada languages:
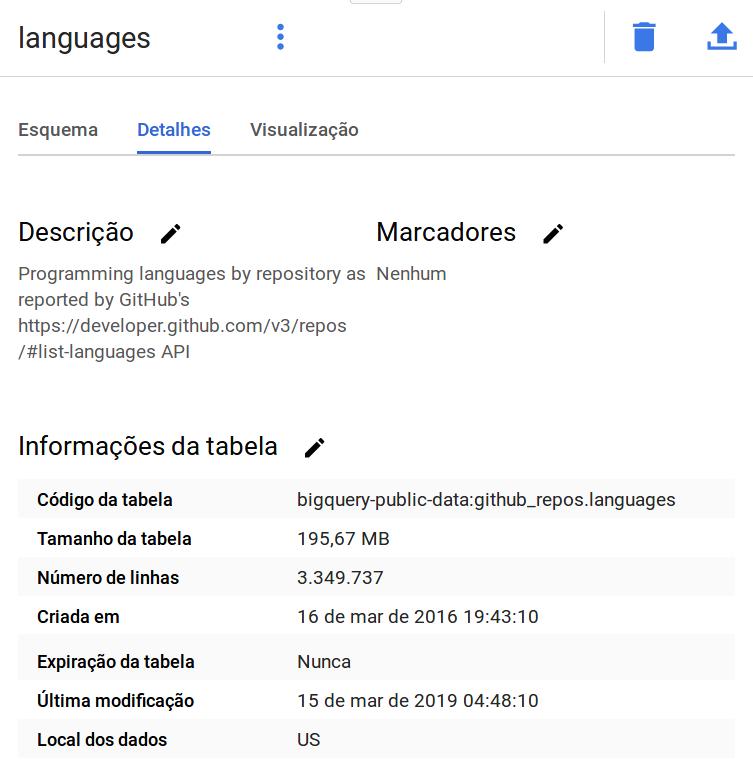
Essa tabela embora grande tem poucas colunas, apenas 4 para ser mais exata:
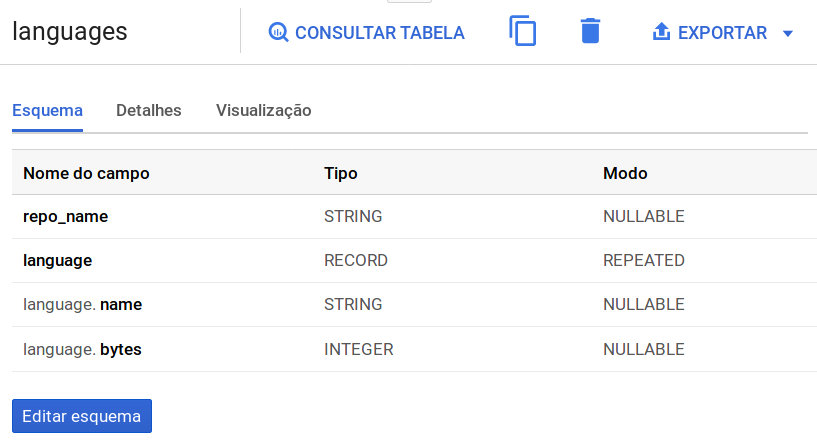
Com o BigQuery é possível exportar dados para a sua conta do Google Drive. E foi isso que eu fiz, primeiro eu selecionei 100 observacoes da tabela usando a consulta SQL abaixo:
SELECT * FROM `bigquery-public-data.github_repos.languages` LIMIT 100
E após a query ter sido executada eu cliquei na telinha do próprio BigQuery para exportar os resultados. Ao exportar esses dados o BigQuery cria uma pasta no seu Drive:
E dentro dessa pasta um arquivo com o mesmo nome de extensão .json. Eu baixei esse arquivo e renomeei ele para bq-github-languages.json só para ser um nome mais indicativo do dado que ele contém.
Se você abrir esse arquivo você vai notar uma coisa que pode ser curiosa: Ao invés de ter um único JSON, o arquivo traz na verdade vários JSONs separados - um JSON para cada observação da tabela e isso nos traz ao nosso primeiro método.
.load()
O json.load() recebe um algo que seja “readable” ou seja, qualquer estrutura Python que tenha o método .read() embutido. Podemos encontrar esse comportamento por exemplo, em arquivos.
Então, se o nosso arquivo tivesse um grande JSON contendo as nossas observações, poderíamos usar esse método assim:
with open('bq-github-languages.json') as file_data:
data = json.load(file_data)
Se você tentar fazer isso para carregar os dados do nosso arquivo, você ira dar de cara com um erro:
JSONDecodeError: Extra data: line 2 column 1
O que faz total sentindo já que não temos apenas um JSON no nosso arquivo e sim uma coleção deles, não é mesmo? Isso gera a obrigação de ler cada linha do arquivo assim:
with open('bq-github-languages.json') as file_data:
data = file_data.readlines()
E tudo bem, mas essa ação traz o seguinte resultado: no lugar de ter uma lista com vários dicionários, você acaba com uma lista de strings. E se a ideia era manipular esses dados, strings não são a estrutura de dados mais indicadas. O que nos leva ao próximo método,
.loads()
Eu costumava confundir muito o funcionamento dos dois métodos. Até que, recentemente, algo clicou. Quando você tem strings, você deve usar .loads(). Você pode usar a dica que vem do próprio nome: s de string.

Aí depois de ler o arquivo linha a linha com o .readlines() você pode passar item a item da sua lista de strings e transformar ela num dicionário:
for i, item in enumerate(data):
data[i] = json.loads(item)
ou até mesmo usar list comprehensions pra isso:
data = [json.loads(d) for d in data]
E aí podemos ver o resultado disso, data[0] vai trazer algo parecido com isso:
{'repo_name': 'gopz4u/ready',
'language': [{'name': 'C#', 'bytes': '27779'},
{'name': 'C++', 'bytes': '28415'},
{'name': 'CSS', 'bytes': '6475'},
{'name': 'HTML', 'bytes': '34293'},
{'name': 'Java', 'bytes': '117831'},
{'name': 'JavaScript', 'bytes': '205287'},
{'name': 'Objective-C', 'bytes': '118096'}]}
Massa né? Bem, por hoje é só!




