A resposta simples: Nuvem! Vamos ver na prática como é viver com seus Jupyter Notebooks na nuvem? Vaaamoooss!!!
Uns dois anos atrás, enquanto eu estava trabalhando na Operação Serenata de Amor, meus colegas de trabalho costumavam dizer que eu tinha um computador da Xuxa ou algo tipo assim:
 Fonte
FonteNada contra os computadores da Xuxa ou o Pense Bem, mas se você considerar que no trabalho com ciência de dados, machine learning, inteligência artificial e afins, nem o computador da Xuxa, nem o Pense Bem e, nem tão pouco 4GB de RAM, vão ser o suficiente para rodar tarefas que requerem grandes quantidades de dados em memória ao mesmo tempo.
Enquanto cientista de dados, a maior parte do trabalho envolve tarefas “pesadas”. Uma solução para resolver rapidamente a falta de capacidade de processamento do computador é o uso de uma máquina na nuvem.
Vantagens
Mas o que faz a nuvem tão diferente assim? E o que faz dela um lugar tão mágico?
Hoje, um dos maiores desafios de ciência de dados e mais especificamente da área de big data é conseguir processar uma quantidade enorme de dados em pouco tempo e sem gastar muito para isso. E, nessas horas, a nuvem é seu maior aliado.
Hoje, no Brasil, você não encontra um Notebook leve com uma configuração robusta, com mais do que 16GB de RAM e um SSD com mais do que 128GB, por menos de 7 mil reais. Desembolsar essa quantidade de dinheiro está além da realidade financeira da maioria das pessoas.
Data centers de gigantes da tecnologia, como Digital Ocean (DO), Amazon Web Services (AWS), Google Cloud e Azure, têm disponibilizado acesso de baixo custo a máquinas com capacidade de processamento maior que os tais notebooks de 7 mil reais. Além disso, uma conexão com pouca largura de banda é o suficiente para acessar sua máquina na nuvem e colocar os scripts para rodarem.
Essas máquinas disponíveis conseguem, em questão de poucas horas, executar processamentos que levariam dias ou mesmo não iriam rodar em computadores convencionais.
Desvantagens
Mas a nuvem não é só feita de vantagens, existem alguns pontos que ainda me incomodam ao usá-la. Por exemplo, todos as empresas que oferecem esse tipo de serviço com qualidade irrefutável são gringas e cobram em dólares. Ainda falta um serviço brasileiro que seja barato e confiável o suficiente para nos fazer trocar os serviços oferecidos pela DO e pela AWS por exemplo.
Ainda ouso dizer que, por mais que as máquinas sejam plug-and-play, é necessário que algumas pequenas configurações sejam realizadas para de fato garantir a usabilidade mínima, obrigando assim ao cientista de dados a ter mais de um chapéu e, nesse caso, assumir o chapéu SysAdmin da coisa.
Jupyter in the cloud with diamonds
Okay, mas vamos supor que você já tem sua máquina maravilha bonitinha lá no insira-aqui-seu-serviço-de-nuvem-favorito. E aí? Como fica o Jupyter Notebook?
A Ana Schwendler já falou aqui sobre como os cientistas do Serenata usam Jupyter Notebooks para explorar os dados e validar ou negar hipóteses. Normalmente, o notebook é rodado localmente na máquina de quem esteja programando, mas quando a pessoa começa a usar uma máquina na nuvem como rola esse processo?
Vivendo nas nuvens

Fonte
O jeito mais prático de acessar uma máquina na nuvem é via conexão SSH. O SSH é um protocolo que permite acessar máquinas remotamente de forma segura. Existem formas de estabelecer uma conexão SSH usando programas como o PuTTY e o MobaXterm, mas se você tiver acesso a um terminal, você também pode fazer isso usando um comando, passando seu usuário na máquina remota e o endereço (host) dessa máquina, algo assim:
|
Mas o que é esse SSH finalmente e como ele funciona? Na prática, o SSH nada mais é que um jeito seguro de fazer login num computador que não está pertinho de você e ele funciona como uma chave e um cadeado. Quando você vai entrar em casa, normalmente você tem que destrancar o cadeado, e o SSH funciona exatamente da mesma forma, você tem um par de arquivos que são chamados de chave e cumprem o papel da chave e o cadeado de casa.
Aí, ao invés de fazer um login tradicional com usuário e senha, você pode usar o SSH para se conectar a sua máquina na nuvem. Basta que no servidor tenha o seu cadeado (chave pública) e que você tenha a chave (chave privada) na sua máquina local. Pra quem usa programas como os que falei anteriormente, esses programas se encarregam de gerenciar essas chaves para você.
Num servidor Linux, o lugar padrão para encontrar os cadeados é o arquivo authorized_keys dentro da pasta .ssh. O mais legal é que uma mesma máquina pode ter várias chaves públicas dentro desse arquivo assim, todo o time que precisar acessar aquela máquina consegue. Isso permite por exemplo, o compartilhamento de recursos entre os integrantes do time, barateando ainda mais os custos para rodar tarefas pesadas.
Hoje em dia, por trabalhar de um computador com o Windows, mas tendo familiaridade com o Linux — eu uso o Git Bash, um terminal Bash distribuído com a instalação do Git e muito útil ❤. Acessar a máquina na nuvem via linha de comando funciona pra mim, mas se você preferir usar programas, fique à vontade, o gosto é do freguês e você deve escolher aquilo que for mais confortável para você 😉. Daqui pra frente eu vou mostrar como usar o terminal para fazer o que a gente precisa. Então, para acessar uma máquina usando o terminal basta fazer o seguinte:
|
e você tá lá nas nuvens 😉
Vamos entender o comando:
ssh: é o programa para estabelecer uma conexão SSH;jessicatemporal: é o meu usuário de acesso na máquina lá na nuvem;34.66.48.61: é o endereço de IP da máquina que estou querendo acessar (aqui estou mostrando pra você um IP fictício apenas para exemplificar, tá?).
Agora que você acessou a sua máquina você pode rodar o Jupyter Notebook:
|
Note que eu passei um parâmetro a mais ali o--no-browser que serve para o Jupyter Notebook rodar sem abrir um navegador.
Vivendo de portais
Quando rodamos o Jupyter Notebook no nosso computador, um canal de comunicação é escolhido para que a gente possa visualizar nossos notebooks, esse canal é conhecido como porta e, na configuração padrão do Jupyter, é a 8888. Assim a gente consegue acessar no nosso navegador o caminho [https://localhost:8888](http://localost:8888) e rodar nossos notebooks certo?
Mas, agora o Jupyter não está rodando no seu computador local então, vamos usar a nossa conexão SSH para ligar uma das portas do nosso computador com a porta do servidor em que o Jupyter está rodando. Para isso, você usa o argumento -L que gera o que é conhecido como port forwarding. Seu acesso SSH ficaria mais ou menos assim:
|
Em termos não técnicos, o port forwarding funciona como um portal.

Fonte
Se você cria um portal para algum lugar consegue ver o que está acontecendo nesse lugar. Também é assim que a gente consegue estabelecer um canal de comunicação e saber o que está rolando no servidor, criando um túnel (portal) que liga a porta 8080 da minha máquina local a porta 8888 do servidor:
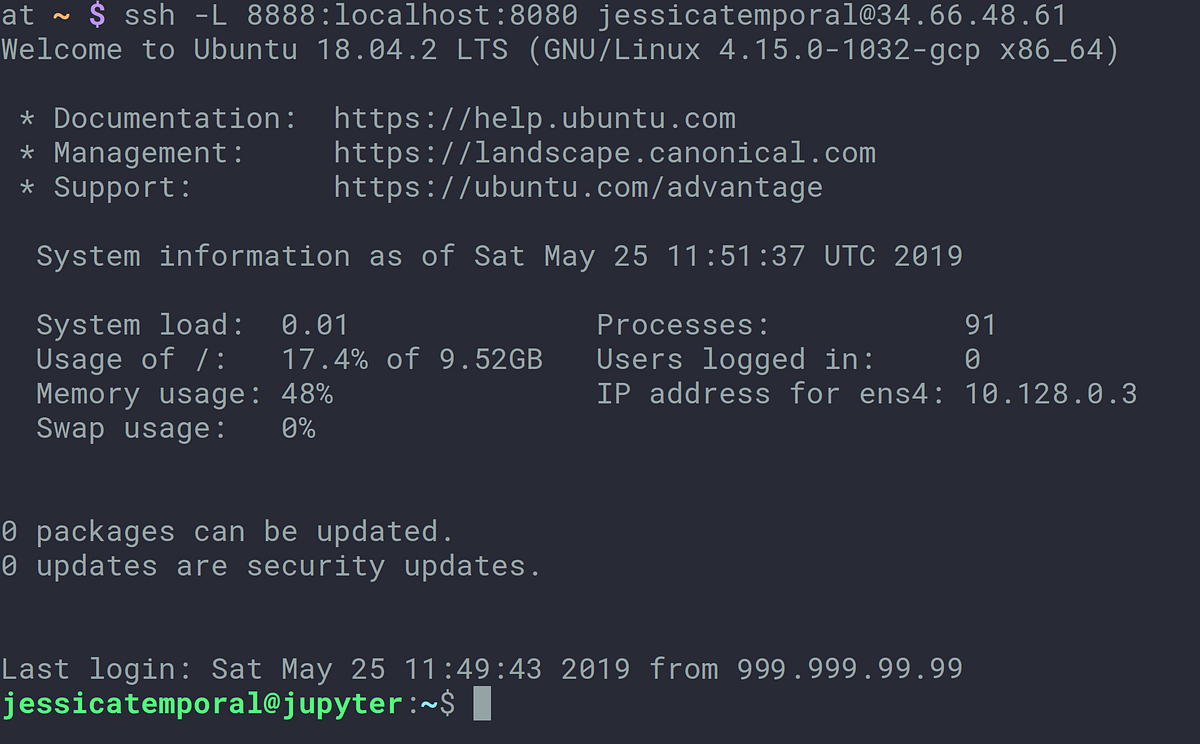
Com isso você consegue abrir no navegador do seu computador e acessar o https://localhost:8080 para ver seus notebooks:
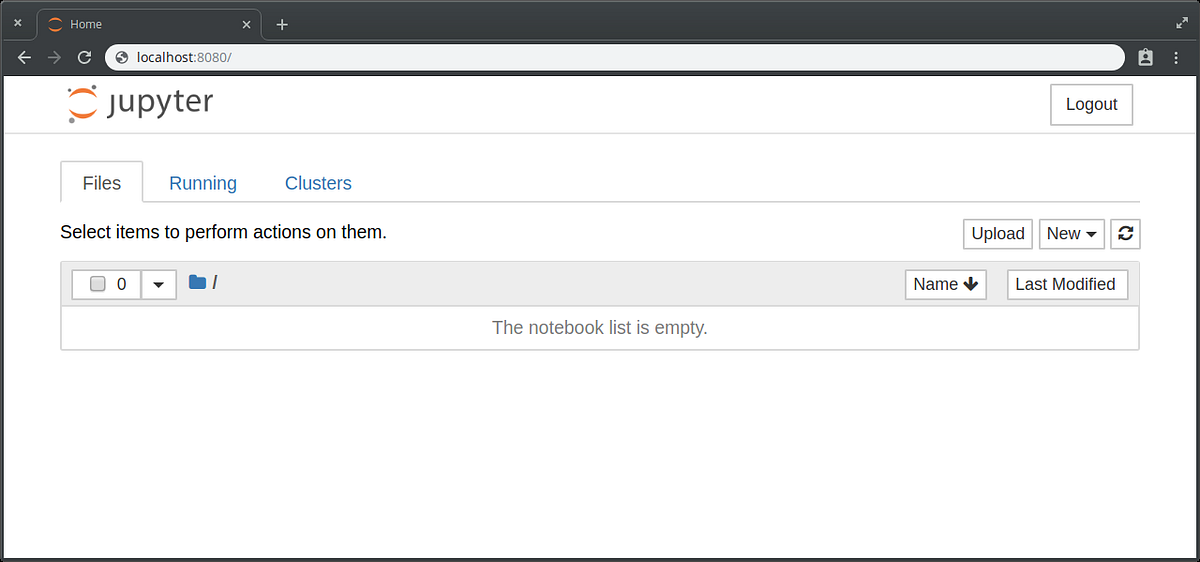
Finalmente
Depois de colocar seu Jupyter para rodar na nuvem, e acessá-lo usando o túnel, a construção do notebook em si não muda muita coisa. Você irá continuar a fazer suas análises como normalmente faz, com a pequena diferença que agora você tem o poder da nuvem ao seu alcance.

Fonte
Agora vai lá e conquiste a nuvem você também! Xêro.
Dicas
Se quiser aprender mais sobre o SSH recomendo:
- Ler o manual dele a medida que precisar;
- Esse post que faz um curso rápido de SSH;
- Esse infográfico de referência sobre o SSH;
- Se você quiser rodar o Jupyter numa instância do Google Cloud esse post aqui tá guardado no coração.

{kind=link}
{kind=link}
{kind=link}